
Credits: Jay Conrod
Echoed from:
http://www.jayconrod.com/posts/37/a-simple-interpreter-from-scratch-in-python-part-1
http://www.jayconrod.com/posts/37/a-simple-interpreter-from-scratch-in-python-part-2
http://www.jayconrod.com/posts/37/a-simple-interpreter-from-scratch-in-python-part-3
http://www.jayconrod.com/posts/37/a-simple-interpreter-from-scratch-in-python-part-4
The thing that attracted me most to computer science in college was the compiler. I thought it was almost magical how compilers could read even my poorly written source code and generate complicated programs. When I finally took a course in compilers, I found the process to be a lot simpler than I expected.
In this series of articles, I will attempt to capture some of this simplicity by writing an interpreter for a basic imperative language called IMP. The interpreter will be written in Python since it’s a simple, widely known language. Python code looks like pseudocode, so even if you don’t know Python, you’ll be able to understand it. Parsing will be done with a simple set of parser combinators made from scratch (explained in the next article in this series). No external libraries will be used except for sys (for I/O), re (for regular expressions in the lexer), and unittest (to make sure everything works).
The IMP language
Before we start writing, let’s discuss the language we’ll be interpreting. IMP is a minimal imperative language with the following constructs:
Assignment statements (all variables are global and can only store integers):
x := 1
Conditional statements:
if x = 1 then y := 2 else y := 3 end
While loops:
while x < 10 do x := x + 1 end
Compound statements (separated by semicolons):
x := 1; y := 2
Okay, so it’s just a toy language, but you could easily extend it to be something more useful like Lua or Python. I wanted to keep things as simple as possible for this tutorial.
Here’s an example of a program which computes a factorial:
n := 5; p := 1; while n > 0 do p := p * n; n := n - 1 end
IMP provides no way to read input, so the initial state must be set with a series of assignment statements at the beginning of the program. There is also no way to print results, so the interpreter will print the values of all variables at the end of the program.
Structure of the interpreter
The core of the interpreter is the intermediate representation (IR). This is how we represent IMP programs in memory. Since IMP is such a simple language, the intermediate representation will correspond directly to the syntax of the language; there will be a class for each kind of expression or statement. In a more complicated language, you would want not only a syntactic representation but also a semantic representation which is easier to analyze or execute.
The interpreter will execute in three stages:
- Split characters in the source code into tokens
- Organize the tokens into an abstract syntax tree (AST). The AST is our intermediate representation.
- Evaluate the AST and print the state at the end
The process of splitting characters into tokens is called lexing and is performed by a lexer. Tokens are short, easily digestible strings that contain the most basic parts of the program such as numbers, identifiers, keywords, and operators. The lexer will drop whitespace and comments, since they are ignored by the interpreter.
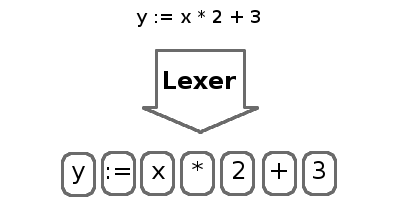
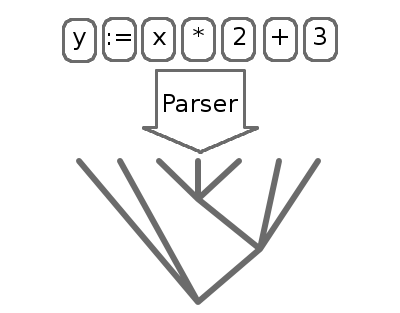
The process of organizing tokens into an abstract syntax tree (AST) is called parsing. The parser extracts the structure of the program into a form we can evaluate.
The process of actually executing the parsed AST is called evaluation. This is actually the simplest part of the interpreter.
This article will focus solely on the lexer. We will write a generic lexer library, then use it to create a lexer for IMP. The next articles will focus on the parser and the evaluator.
The lexer library
The operation of the lexer is fairly simple. It is heavily based on regular expressions, so if you’re not familiar with them, you might want to read up. In short, a regular expression is a specially formatted string that describes other strings. You can use them to match strings like phone numbers or e-mail addresses, or in our case, different kinds of tokens.
The input to the lexer will be just a stream of characters. To keep things simple, we will read an entire input file into memory. The output will be a list of tokens. Each token comprises a value (the string it represents) and a tag (to indicate what kind of token it is). The parser will use both to decide how to create the AST.
Since the operation of a lexer for any language is pretty similar, we will create a generic lexer which takes a list of regular expressions and corresponding tags. For each expression, it will check whether the input text matches at the current position. If a match is found, the matching text is extracted into a token, along with the regular expression’s tag. If the regular expression has no tag associated with it, the text is discarded. This lets us get rid of junk characters, like comments and whitespace. If there is no matching regular expression, we report an error and quit. This process is repeated until there are no more characters left to match.
Here is the code from the lexer library:
import sys
import re
def lex(characters, token_exprs):
pos = 0
tokens = []
while pos < len(characters):
match = None
for token_expr in token_exprs:
pattern, tag = token_expr
regex = re.compile(pattern)
match = regex.match(characters, pos)
if match:
text = match.group(0)
if tag:
token = (text, tag)
tokens.append(token)
break
if not match:
sys.stderr.write('Illegal character: %s\\n' % characters[pos])
sys.exit(1)
else:
pos = match.end(0)
return tokens
Note that the order we pass in the regular expressions is significant. lex will iterate over the expressions and will accept the first one that matches. This means, when using lex, we should put the most specific expressions first (like those matching operators and keywords), followed by the more general expressions (like those for identifiers and numbers).
The IMP lexer
Given the lex function above, defining a lexer for IMP is very simple. The first thing we do is define a series of tags for our tokens. IMP only needs three tags. RESERVED indicates a reserved word or operator. INT indicates a literal integer. ID is for identifiers.
import lexer RESERVED = 'RESERVED' INT = 'INT' ID = 'ID'
Next we define the token expressions that will be used in the lexer. The first two expressions match whitespace and comments. These have no tag, so lex will drop any characters that they match.
token_exprs = [
(r'[ \n\t]+', None),
(r'#[^\n]*', None),
After that, we have all our operators and reserved words. Remember, the “r” before each regular expression means the string is “raw”; Python will not handle any escape characters. This allows us to include backslashes in the strings, which are used by the regular expression engine to escape operators like “+” and “*”.
(r'\:=', RESERVED),
(r'\(', RESERVED),
(r'\)', RESERVED),
(r';', RESERVED),
(r'\+', RESERVED),
(r'-', RESERVED),
(r'\*', RESERVED),
(r'/', RESERVED),
(r'<=', RESERVED),
(r'<', RESERVED),
(r'>=', RESERVED),
(r'>', RESERVED),
(r'=', RESERVED),
(r'!=', RESERVED),
(r'and', RESERVED),
(r'or', RESERVED),
(r'not', RESERVED),
(r'if', RESERVED),
(r'then', RESERVED),
(r'else', RESERVED),
(r'while', RESERVED),
(r'do', RESERVED),
(r'end', RESERVED),
Finally, we have expressions for integers and identifiers. Note that the regular expression for identifiers would match all of the reserved words above, so it is important that this comes last.
(r'[0-9]+', INT),
(r'[A-Za-z][A-Za-z0-9_]*', ID),
]
Now that our regular expressions are defined, we need to create an actual lexer function.
def imp_lex(characters):
return lexer.lex(characters, token_exprs)
If you’re curious to try this, here’s some driver code to test it out:
import sys
from imp_lexer import *
if __name__ == '__main__':
filename = sys.argv[1]
file = open(filename)
characters = file.read()
file.close()
tokens = imp_lex(characters)
for token in tokens:
print token
What are parser combinators?
There are many, many ways to build a parser. Combinators are probably the easiest and fastest way to get a parser up and running.
You can think of a parser as a function. It accepts a stream of tokens as input. If successful, the parser will consume some tokens from the stream. It will return part of the final AST, along with the remaining tokens. A combinator is a function which produces a parser as its output, usually after taking one or more parsers as input, hence the name “combinator”. You can use combinators to create a complete parser for a language like IMP by creating lots of smaller parsers for parts of the language, then using combinators to build the final parser.
A minimal combinator library
Parser combinators are fairly generic, and can be used with any language. As we did with the lexer, we’ll start by writing a language agnostic library of combinators, then use that to write our IMP parser.
First, let’s define a Result class. Every parser will return a Result object on success or None on failure. A Result comprises a value (part of the AST), and a position (the index of the next token in the stream).
class Result:
def __init__(self, value, pos):
self.value = value
self.pos = pos
def __repr__(self):
return 'Result(%s, %d)' % (self.value, self.pos)
Next, we’ll define a base class, Parser. Earlier, I said parsers are functions which take a stream of tokens as input. We will actually be defining parsers as objects with a __call__ method. This means that a parser object will behave as if it were a function, but we can also provide additional functionality by defining some operators.
class Parser:
def __call__(self, tokens, pos):
return None # subclasses will override this
def __add__(self, other):
return Concat(self, other)
def __mul__(self, other):
return Exp(self, other)
def __or__(self, other):
return Alternate(self, other)
def __xor__(self, function):
return Process(self, function)
The method that actually does the parsing is __call__. The input is the full list of tokens (returned by the lexer) and an index into the list indicating the next token. The default implementation always returns None (failure). Subclasses of Parser will provide their own __call__ implementation.
The other methods, __add__, __mul__, __or__, and __xor__ define the +, *, |, and ^ operators, respectively. Each operator provides a shortcut for calling a different combinator. We’ll cover each of these combinators shortly.
Next, we’ll look at the simplest combinator, Reserved. Reserved will be used to parse reserved words and operators; it will accept tokens with a specific value and tag. Remember, tokens are just value-tag pairs. token[0] is the value, token[1] is the tag.
class Reserved(Parser):
def __init__(self, value, tag):
self.value = value
self.tag = tag
def __call__(self, tokens, pos):
if pos < len(tokens) and \
tokens[pos][0] == self.value and \
tokens[pos][1] is self.tag:
return Result(tokens[pos][0], pos + 1)
else:
return None
At this point, you might stop and say, “I thought combinators were going to be functions returning parsers. This subclass doesn’t look like a function.” It is like a function though, if you think of a constructor as a function which returns an object (which in this case also happens to be callable). Subclassing is an easy way to define a new combinator since all we need to do is provide a constructor and a __call__ method, and we still retain other functionality (like the overloaded operators).
Moving on, the Tag combinator is very similar to Reserved. It matches any token which has a particular tag. The value can be anything.
class Tag(Parser):
def __init__(self, tag):
self.tag = tag
def __call__(self, tokens, pos):
if pos < len(tokens) and tokens[pos][1] is self.tag:
return Result(tokens[pos][0], pos + 1)
else:
return None
The Tag and Reserved combinators are our primitives. All combinators will be built out of them at the most basic level.
The Concat combinator will take two parsers as input (left and right). When applied, a Concat parser will apply the left parser, followed by the right parser. If both are successful, the result value will be a pair containing the left and right results. If either parser is unsuccessful, None is returned.
class Concat(Parser):
def __init__(self, left, right):
self.left = left
self.right = right
def __call__(self, tokens, pos):
left_result = self.left(tokens, pos)
if left_result:
right_result = self.right(tokens, left_result.pos)
if right_result:
combined_value = (left_result.value, right_result.value)
return Result(combined_value, right_result.pos)
return None
Concat is useful for parsing specific sequences of tokens. For instance, to parse 1 + 2, you could write:
parser = Concat(Concat(Tag(INT), Reserved('+', RESERVED)), Tag(INT))
or more concisely using the + operator shorthand:
parser = Tag(INT) + Reserved('+', RESERVED) + Tag(INT)
The Alternate combinator is similar. It also takes left and right parsers. It starts by applying the left parser. If successful, that result is returned. If unsuccessful, it applies the right parser and returns its result.
class Alternate(Parser):
def __init__(self, left, right):
self.left = left
self.right = right
def __call__(self, tokens, pos):
left_result = self.left(tokens, pos)
if left_result:
return left_result
else:
right_result = self.right(tokens, pos)
return right_result
Alternate is useful for choosing among several possible parsers. For instance, if we wanted to parse any binary operator:
parser = Reserved('+', RESERVED) |
Reserved('-', RESERVED) |
Reserved('*', RESERVED) |
Reserved('/', RESERVED)
Opt is useful for optional text, such as the else-clause of an if-statement. It takes one parser as input. If that parser is successful when applied, the result is returned normally. If it fails, a successful result is still returned, but the value of that result is None. No tokens are consumed in the failure case; the result position is the same as the input position.
class Opt(Parser):
def __init__(self, parser):
self.parser = parser
def __call__(self, tokens, pos):
result = self.parser(tokens, pos)
if result:
return result
else:
return Result(None, pos)
Rep applies its input parser repeatedly until it fails. This is useful for generating lists of things. Note that Rep will successfully match an empty list and consume no tokens if its parser fails the first time it’s applied.
class Rep(Parser):
def __init__(self, parser):
self.parser = parser
def __call__(self, tokens, pos):
results = []
result = self.parser(tokens, pos)
while result:
results.append(result.value)
pos = result.pos
result = self.parser(tokens, pos)
return Result(results, pos)
Process is a useful combinator which allows us to manipulate result values. Its input is a parser and a function. When the parser is applied successfully, the result value is passed to the function, and the return value from the function is returned instead of the original value. We will use Process to actually build the AST nodes out of the pairs and lists that Concat and Rep return.
class Process(Parser):
def __init__(self, parser, function):
self.parser = parser
self.function = function
def __call__(self, tokens, pos):
result = self.parser(tokens, pos)
if result:
result.value = self.function(result.value)
return result
As an example, consider the parser we built with Concat. When it parses 1 + 2, the result value we actually get back is (('1', '+'), '2'), which is not very useful. With Process we can change that result. For example, the following parser would sum the parsed expression.
def process_func(parsed):
((l, _), r) = parsed
return int(l) + int(r)
better_parser = parser ^ process_func
Lazy is a less obviously useful combinator. Instead of taking an input parser, it takes a zero-argument function which returns a parser. Lazy will not call the function to get the parser until it’s applied. This is needed to build recursive parsers (like how arithmetic expressions can include arithmetic expressions). Since such a parser refers to itself, we can’t just define it by referencing it directly; at the time the parser’s defining expression is evaluated, the parser is not defined yet. We would not need this in a language with lazy evaluation like Haskell or Scala, but Python is anything but lazy.
class Lazy(Parser):
def __init__(self, parser_func):
self.parser = None
self.parser_func = parser_func
def __call__(self, tokens, pos):
if not self.parser:
self.parser = self.parser_func()
return self.parser(tokens, pos)
The next combinator, Phrase, takes a single input parser, applies it, and returns its result normally. The only catch is that it will fail if its input parser did not consume all of the remaining tokens. The top level parser for IMP will be a Phrase parser. This prevents us from partially matching a program which has garbage at the end.
class Phrase(Parser):
def __init__(self, parser):
self.parser = parser
def __call__(self, tokens, pos):
result = self.parser(tokens, pos)
if result and result.pos == len(tokens):
return result
else:
return None
The last combinator is unfortunately the most complicated. Exp is fairly specialized; it’s used to match an expression which consists of a list of elements separated by something. Here’s an example with compound statements:
a := 10; b := 20; c := 30
In this case, we have a list of statements separated by semicolons. You might think that we don’t need Exp since we can do the same thing with the other combinators. We could just write a parser for the compound statement like this:
def compound_stmt():
return stmt() + Reserved(';', RESERVED) + stmt()
Think about how stmt might be defined though.
def stmt():
return Lazy(compound_stmt) | assign_stmt()
So stmt starts by calling compound_stmt, which starts by calling stmt. These parsers will call each other over and over without getting anything done until we get a stack overflow. This problem is not limited to compound statements; arithmetic and Boolean expressions have the same problem (think about operators like + or and as the separators). This problem is called left recursion, and parser combinators are bad at it.
Fortunately, Exp provides a way to work around left recursion, just by matching a list, similar to the way Rep does. Exp takes two parsers as input. The first parser matches the actual elements of the list. The second matches the separators. On success, the separator parser must return a function which combines elements parsed on the left and right into a single value. This value is accumulated for the whole list, left to right, and is ultimately returned.
Let’s look at the code:
class Exp(Parser):
def __init__(self, parser, separator):
self.parser = parser
self.separator = separator
def __call__(self, tokens, pos):
result = self.parser(tokens, pos)
def process_next(parsed):
(sepfunc, right) = parsed
return sepfunc(result.value, right)
next_parser = self.separator + self.parser ^ process_next
next_result = result
while next_result:
next_result = next_parser(tokens, result.pos)
if next_result:
result = next_result
return result
result will always contain everything that’s been parsed so far. process_next is a function that can be used with Process. next_parser will apply separator followed by parser to get the next element of the list. process_next will create a new result by applying the separator function to the current result and the newly parsed element. next_parser is applied in a loop until it can’t match any more elements.
Let’s see how Exp can be used to solve our compound_stmt problem.
def assign_stmt():
...
def compound_sep():
def process_sep(parsed):
return lambda l, r: CompoundStmt(l, r)
return Reserved(';', RESERVED) ^ process_sep
def compound_stmt():
return Exp(assign_stmt(), compound_sep())
We could also write this as:
def compound_stmt():
return assign_stmt() * compound_sep()
Defining the AST
Before we can actually start writing our parsers, we need to define the data structures that will be the output of our parser. We will do this with classes. Every syntactic element of IMP will have a corresponding class. Objects of these classes will represent nodes in the AST.
There are three kinds of structures in IMP: arithmetic expressions (used to compute numbers), Boolean expressions (used to compute conditions for if- and while-statements), and statements. We will start with arithmetic expressions, since the other two elements depend on them.
An arithmetic expression can take one of three forms:
- Literal integer constants, such as
42 - Variables, such as
x - Binary operations, such as
x + 42. These are made out of other arithmetic expressions.
We can also group expressions together with parenthesis (like (x + 2) * 3. This isn’t a different kind of expression so much as a different way to parse the expression.
We will define three classes for these forms, plus a base class for arithmetic expressions in general. For now, the classes won’t do much except contain data. We will include a __repr__ method, so we can print out the AST for debugging. All AST classes will subclass Equality so we can check if two AST objects are the same. This helps with testing.
from equality import *
class Aexp(Equality):
pass
class IntAexp(Aexp):
def __init__(self, i):
self.i = i
def __repr__(self):
return 'IntAexp(%d)' % self.i
class VarAexp(Aexp):
def __init__(self, name):
self.name = name
def __repr__(self):
return 'VarAexp(%s)' % self.name
class BinopAexp(Aexp):
def __init__(self, op, left, right):
self.op = op
self.left = left
self.right = right
def __repr__(self):
return 'BinopAexp(%s, %s, %s)' % (self.op, self.left, self.right)
Boolean expressions are a little more complicated. There are four kinds of Boolean expressions.
- Relational expressions (such as
x < 10) - And expressions (such as
x < 10 and y > 20) - Or expressions
- Not expressions
The left and right sides of a relational expression are arithmetic expressions. The left and right sides of an “and”, “or”, or “not” expression are Boolean expressions. Restricting the type like this helps us avoid nonsensical expressions like “x < 10 and 30”.
class Bexp(Equality):
pass
class RelopBexp(Bexp):
def __init__(self, op, left, right):
...
class AndBexp(Bexp):
def __init__(self, left, right):
...
class OrBexp(Bexp):
def __init__(self, left, right):
...
class NotBexp(Bexp):
def __init__(self, exp):
...
Statements can contain both arithmetic and Boolean expressions. There are four kinds of statements: assignment, compound, conditional, and loop.
class Statement(Equality):
pass
class AssignStatement(Statement):
def __init__(self, name, aexp):
...
class CompoundStatement(Statement):
def __init__(self, first, second):
...
class IfStatement(Statement):
def __init__(self, condition, true_stmt, false_stmt):
...
class WhileStatement(Statement):
def __init__(self, condition, body):
...
Primitives
Now that we have our AST classes and a convenient set of parser combinators, it’s time to write our parser. When writing a parser, it’s usually easiest to start with the most basic structures of the language and work our way up.
The first parser we’ll look at is the keyword parser. This is just a specialized version of the Reserved combinator using the RESERVED tag that all keyword tokens are tagged with. Remember, Reserved matches a single token where both the text and tag are the same as the ones given.
def keyword(kw):
return Reserved(kw, RESERVED)
keyword is actually a combinator because it is a function that returns a parser. We will use it directly in other parsers though.
The id parser is used to match variable names. It uses the Tag combinator, which matches a token with the specified tag.
id = Tag(ID)
The num parser is used to match integers. It works just like id, except we use the Process combinator (actually the ^ operator, which calls Process) to convert the token into an actual integer value.
num = Tag(INT) ^ (lambda i: int(i))
Parsing arithmetic expressions
Parsing arithmetic expressions is not particularly simple, but since we need to parse arithmetic expressions in order to parse Boolean expressions or statements, we will start there.
We’ll first define the aexp_value parser, which will convert the values returned by num and id into actual expressions.
def aexp_value():
return (num ^ (lambda i: IntAexp(i))) | \
(id ^ (lambda v: VarAexp(v)))
We’re using the | operator here, which is a shorthand for the Alternate combinator. So this will attempt to parse an integer expression first. If that fails, it will try to parse a variable expression.
You’ll notice that we defined aexp_value as a zero-argument function instead of a global value, like we did with id and num. We’ll do the same thing with all the other parsers. The reason is that we don’t want the code for each parser to be evaluated right away. If we defined every parser as a global, each parser would not be able to reference parsers that come after it in the same source file, since they would not be defined yet. This would make recursive parsers impossible to define, and the source code would be awkward to read.
Next, we’d like to support grouping with parenthesis in our arithmetic expressions. Although grouped expressions don’t require their own AST class, they do require another parser to handle them.
def process_group(parsed):
((_, p), _) = parsed
return p
def aexp_group():
return keyword('(') + Lazy(aexp) + keyword(')') ^ process_group
process_group is a function we use with the Process combinator (^ operator). It just discards the parenthesis tokens and returns the expression in between. aexp_group is the actual parser. Remember, the + operator is shorthand for the Concat combinator. So this will parse '(', followed by an arithmetic expression (parsed by aexp, which we will define soon), followed by ')'. We need to avoid calling aexp directly since aexp will call aexp_group, which would result in infinite recursion. To do this, we use the Lazy combinator, which defers the call to aexp until the parser is actually applied to some input.
Next, we combine aexp_value and aexp_group using aexp_term. An aexp_term expression is any basic, self-contained expression where we don’t have to worry about operator precedence with respect to other expressions.
def aexp_term():
return aexp_value() | aexp_group()
Now we come to the tricky part: operators and precedence. It would be easy for us just to define another kind of aexp parser and throw it together with aexp_term. This would result in a simple expression like:
1 + 2 * 3
being parsed incorrectly as:
(1 + 2) * 3
The parser needs to be aware of operator precedence, and it needs to group together operations with higher precedence.
We will define a few helper functions in order to make this work.
def process_binop(op):
return lambda l, r: BinopAexp(op, l, r)
process_binop is what actually constructs BinopAexp objects. It takes any arithmetic operator and returns a function that combines a pair of expressions using that operator.
process_binop will be used with the Exp combinator (* operator). Exp parses a list of expressions with a separator between each pair of expressions. The left operand of Exp is a parser that will match individual elements of the list (arithmetic expressions in our case). The right operand is a parser that will match the separators (operators). No matter what separator is matched, the right parser will return a function which, given the matched separator, returns a combining function. The combining function takes the parsed expressions to the left and right of the separator and returns a single, combined expression. Confused yet? We’ll go through the usage of Exp shortly. process_binop is actually what will be returned by the right parser.
Next, we’ll define our precedence levels and a combinator to help us deal with them.
def any_operator_in_list(ops):
op_parsers = [keyword(op) for op in ops]
parser = reduce(lambda l, r: l | r, op_parsers)
return parser
aexp_precedence_levels = [
['*', '/'],
['+', '-'],
]
any_operator_in_list takes a list of keyword strings and returns a parser that will match any of them. We will call this on aexp_precedence_levels, which contains a list of operators for each precedence level (highest precedence first).
def precedence(value_parser, precedence_levels, combine):
def op_parser(precedence_level):
return any_operator_in_list(precedence_level) ^ combine
parser = value_parser * op_parser(precedence_levels[0])
for precedence_level in precedence_levels[1:]:
parser = parser * op_parser(precedence_level)
return parser
precedence is the real meat of the operation. Its first argument, value_parser is a parser than can read the basic parts of an expression: numbers, variables, and groups. That will be aexp_term. precedence_levels is a list of lists of operators, one list for each level. We’ll use aexp_precedence_levels for this. combine will take a function which, given an operator, returns a function to build a larger expression out of two smaller expressions. That’s process_binop.
Inside precedence, we first define op_parser which, for a given precedence level, reads any operator in that level and returns a function which combines two expressions. op_parser can be used as the right-hand argument of Exp. We start by calling Exp with op_parser for the highest precedence level, since these operations need to be grouped together first. We then use the resulting parser as the element parser (Exp‘s left argument) at the next level. After the loop finishes, the resulting parser will be able to correctly parse any arithmetic expression.
How does this work in practice? Let’s work it through.
E0 = value_parser E1 = E0 * op_parser(precedence_levels[0]) E2 = E1 * op_parser(precedence_levels[1])
E0 is the same as value_parser. It can parse numbers, variables, and groups, but no operators. E1 can parse expressions containing anything E0 can match, separated by operators in the first precedence level. So E1 could match a * b / c, but it would raise an error as soon as it encountered a + operator. E2 can match expressions E2 can match, separated by operators in the next precedence level. Since we only have two precedence levels, E2 can match any arithmetic expression we support.
Let’s do an example. We’ll take a complicated arithmetic expression, and gradually replace each part by what matches it.
4 * a + b / 2 - (6 + c) E0(4) * E0(a) + E0(b) / E0(2) - E0(6+c) E1(4*a) + E1(b/2) - E1(6+c) E2((4*a)+(b/2)-(6+c))
We use precedence to directly define aexp:
def aexp():
return precedence(aexp_term(),
aexp_precedence_levels,
process_binop)
We probably could have defined precedence in a less abstract way, but its strength is that it applies to any situation where operator precedence is a problem. We will use it again to parse Boolean expressions.
Parsing Boolean expressions
With arithmetic expressions out of the way, we can move on to Boolean expressions. Boolean expressions are actually simpler than arithmetic expressions, and we won’t need any new tools to parse them. We’ll start with the most basic Boolean expression, the relation:
def process_relop(parsed):
((left, op), right) = parsed
return RelopBexp(op, left, right)
def bexp_relop():
relops = ['<', '<=', '>', '>=', '=', '!=']
return aexp() + any_operator_in_list(relops) + aexp() ^ process_relop
process_relop is just a function that we use with the Process combinator. It just takes three concatenated values and creates a RelopBexp out of them. In bexp_relop, we parse two arithmetic expressions (aexp), separated by a relational operator. We use our old friend any_operator_in_list so we don’t have to write a case for every operator. There is no need to use combinators like Exp or precedence since relational expressions can’t be chained together in IMP like they can in other languages.
Next, we define the not expression. not is a unary operation with high precedence. This makes it much easier to parse than and and or expressions.
def bexp_not():
return keyword('not') + Lazy(bexp_term) ^ (lambda parsed: NotBexp(parsed[1]))
Here, we just concatenate the keyword not with a Boolean expression term (which we will define next). Since bexp_not will be used to define bexp_term, we need to use the Lazy combinator to avoid infinite recursion.
def bexp_group():
return keyword('(') + Lazy(bexp) + keyword(')') ^ process_group
def bexp_term():
return bexp_not() | \
bexp_relop() | \
bexp_group()
We define bexp_group and bexp_term pretty much the same way we did for the arithmetic equivalents. Nothing new here.
Next, we need to define expressions which include the and and or operators. These operators actually work the same way arithmetic operators do; both are evaluated left to right, and and has higher precedence.
bexp_precedence_levels = [
['and'],
['or'],
]
def process_logic(op):
if op == 'and':
return lambda l, r: AndBexp(l, r)
elif op == 'or':
return lambda l, r: OrBexp(l, r)
else:
raise RuntimeError('unknown logic operator: ' + op)
def bexp():
return precedence(bexp_term(),
bexp_precedence_levels,
process_logic)
Just like process_binop, process_logic is intended to be used with the Exp combinator. It takes an operator and returns a function which combines two sub-expressions into an expression using that operator. We pass this along to precedence, just like we did with aexp. Writing generic code pays off here, since we don’t have to repeat the complicated expression processing code.
Parsing statements
With aexp and bexp finished, we can start parsing IMP statements. We’ll start with the humble assignment statement.
def assign_stmt():
def process(parsed):
((name, _), exp) = parsed
return AssignStatement(name, exp)
return id + keyword(':=') + aexp() ^ process
Nothing particularly interesting for this one. Next, we’ll look at stmt_list. This will parse a series of statements separated by semicolons.
def stmt_list():
separator = keyword(';') ^ (lambda x: lambda l, r: CompoundStatement(l, r))
return Exp(stmt(), separator)
Remember, we need to use the Exp combinator here instead of doing something simple like stmt() + keyword(';') + stmt() to avoid left recursion.
Next up is the if-statement:
def if_stmt():
def process(parsed):
(((((_, condition), _), true_stmt), false_parsed), _) = parsed
if false_parsed:
(_, false_stmt) = false_parsed
else:
false_stmt = None
return IfStatement(condition, true_stmt, false_stmt)
return keyword('if') + bexp() + \
keyword('then') + Lazy(stmt_list) + \
Opt(keyword('else') + Lazy(stmt_list)) + \
keyword('end') ^ process
The only complexity here is the fact that the else-clause is optional. This makes the process function a little more complicated.
Finally, we have the while-loop:
def while_stmt():
def process(parsed):
((((_, condition), _), body), _) = parsed
return WhileStatement(condition, body)
return keyword('while') + bexp() + \
keyword('do') + Lazy(stmt_list) + \
keyword('end') ^ process
We’ll wrap it all up with stmt:
def stmt():
return assign_stmt() | \
if_stmt() | \
while_stmt()
You’ll notice that both the if and while statements use stmt_list for their bodies rather than stmt. stmt_list is actually our top level definition. We can’t have stmt depend directly on stmt_list, since this would result in a left recursive parser. And since we want if and while statements to be able to have compound statements for their bodies, we use stmt_list directly.
Putting it all together
We now have a parser for every part of the language. We just need to make a couple top level definitions:
def parser():
return Phrase(stmt_list())
parser will parse an entire program. A program is just a list of statements, but the Phrase combinator ensures that we use every token in the file, rather than ending prematurely if there is are garbage tokens at the end.
def imp_parse(tokens):
ast = parser()(tokens, 0)
return ast
imp_parse is the function that clients will call to parse a program. It takes the full list of tokens, calls parser, starting with the first token, and returns the resulting AST.
To test out our parsers (in addition to unit tests), here’s a simple driver program:
import sys
from imp_parser import *
if __name__ == '__main__':
if len(sys.argv) != 3:
sys.stderr.write('usage: %s filename parsername' % sys.argv[0])
sys.exit(1)
filename = sys.argv[1]
file = open(filename)
characters = file.read()
file.close()
tokens = imp_lex(characters)
parser = globals()[sys.argv[2]]()
result = parser(tokens, 0)
print result
This program will read a file (first argument) and parse it with one of the parsers in imp_parse.py (second argument). For example:
$ echo '1 + 2 * 3' >foo.imp $ python imp_parser_driver.py foo.imp aexp Result(BinopAexp(+, IntAexp(1), BinopAexp(*, IntAexp(2), IntAexp(3))), 5)
This should provide a good sandbox for experimentation.
Let’s think about how a program is evaluated normally. At any given time, there is some “point of control,” which indicates what statement the program is going to evaluate next. When the next statement is evaluated, it modifies the state of the program, both by advancing the “point of control” and by changing the values of variables.
To evaluate an IMP program, we need three things.
- Point of control – we need to know the next statement or expression to evaluate.
- Environment – we need a way to model the “state of the program.”
- Evaluation functions – we need to know how the state and point of control should be modified for each statement or expression.
Point of control is the easiest, at least for IMP. We have arranged our intermediate representation in a tree-like structure. We’ll just call the evaluation function for the top-level statement, which will recursively call evaluation functions for statements and expressions inside it. We will essentially be using Python’s point of control as our own point of control. This wouldn’t be as easy for languages with more complicated control structures like functions or exceptions, but we can keep it simple for IMP.
The environment is also easy. IMP only has global variables, so we can model the environment with a simple Python dictionary. Whenever an assignment is made, we will update the variable’s value in the dictionary.
Evaluation functions are really the only thing we need to think about. Each kind of expression will have an evaluation function which will take the current environment and return a value. Arithmetic expressions will return integers, and Boolean expressions will return true or false. Expressions have no side effects, so the environment will not be modified. Each kind of statement will also have an evaluation function. Statements act by modifying the environment so no result will be returned.
Defining evaluation functions
We will define the evaluation functions as methods on our AST classes. This gives each function direct access to the structure it is evaluating. Here are the functions for arithmetic expressions:
class IntAexp(Aexp):
...
def eval(self, env):
return self.i
class VarAexp(Aexp):
...
def eval(self, env):
if self.name in env:
return env[self.name]
else:
return 0
class BinopAexp(Aexp):
...
def eval(self, env):
left_value = self.left.eval(env)
right_value = self.right.eval(env)
if self.op == '+':
value = left_value + right_value
elif self.op == '-':
value = left_value - right_value
elif self.op == '*':
value = left_value * right_value
elif self.op == '/':
value = left_value / right_value
else:
raise RuntimeError('unknown operator: ' + self.op)
return value
You’ll notice we have some extra logic for the case where the programmer uses a variable that hasn’t been defined yet (one that isn’t in the environment dictionary). To keep things simple and to avoid writing an error handling system, we give all undefined variables a 0 value.
In BinopAexp we handle the “unknown operator” case by raising a RuntimeError. The parser cannot create an AST with unknown operators, so we don’t have to worry about this in practice. However, if someone constructs their own AST without the parser, all bets are off.
Here are the functions for Boolean expressions:
class RelopBexp(Bexp):
...
def eval(self, env):
left_value = self.left.eval(env)
right_value = self.right.eval(env)
if self.op == '<':
value = left_value < right_value
elif self.op == '<=':
value = left_value <= right_value
elif self.op == '>':
value = left_value > right_value
elif self.op == '>=':
value = left_value >= right_value
elif self.op == '=':
value = left_value == right_value
elif self.op == '!=':
value = left_value != right_value
else:
raise RuntimeError('unknown operator: ' + self.op)
return value
class AndBexp(Bexp):
...
def eval(self, env):
left_value = self.left.eval(env)
right_value = self.right.eval(env)
return left_value and right_value
class OrBexp(Bexp):
...
def eval(self, env):
left_value = self.left.eval(env)
right_value = self.right.eval(env)
return left_value or right_value
class NotBexp(Bexp):
...
def eval(self, env):
value = self.exp.eval(env)
return not value
These are pretty straightforward. They just use the built-in Python relational and logic operators.
Here are the evaluation functions for each kind of statement:
class AssignStatement(Statement):
...
def eval(self, env):
value = self.aexp.eval(env)
env[self.name] = value
class CompoundStatement(Statement):
...
def eval(self, env):
self.first.eval(env)
self.second.eval(env)
class IfStatement(Statement):
...
def eval(self, env):
condition_value = self.condition.eval(env)
if condition_value:
self.true_stmt.eval(env)
else:
if self.false_stmt:
self.false_stmt.eval(env)
class WhileStatement(Statement):
...
def eval(self, env):
condition_value = self.condition.eval(env)
while condition_value:
self.body.eval(env)
condition_value = self.condition.eval(env)
For AssignStatement, we just evaluate the arithmetic expression on the right side, and update the environment with the resulting value. The programmer is free to redefine variables that have already been assigned.
In CompoundStatement, we just evaluate each statement, one after the other. Keep in mind that a CompoundStatement is allowed anywhere a statement is allowed, so long chains of statements are encoded as nested compound statements.
In IfStatement, we first evaluate the Boolean expression condition. If it’s true, we evaluate the true statement. If it’s false and a false statement was provided, we evaluate the false statement.
In WhileStatement we evaluate the condition at the beginning to check whether the loop body should even be executed once. The condition is evaluated after each iteration of the loop to check if it’s still true.
Putting it all together
We have now built every major component of our interpreter. We just need a driver program to integrate them:
#!/usr/bin/env python
import sys
from imp_parser import *
from imp_lexer import *
def usage():
sys.stderr.write('Usage: imp filename\\n')
sys.exit(1)
if __name__ == '__main__':
if len(sys.argv) != 2:
usage()
filename = sys.argv[1]
text = open(filename).read()
tokens = imp_lex(text)
parse_result = imp_parse(tokens)
if not parse_result:
sys.stderr.write('Parse error!\\n')
sys.exit(1)
ast = parse_result.value
env = {}
ast.eval(env)
sys.stdout.write('Final variable values:\\n')
for name in env:
sys.stdout.write('%s: %s\\n' % (name, env[name]))
The program expects exactly one argument: the name of the file to interpret. It reads in the file and passes it through the lexer and parser, reporting an error if it finds one. We extract the AST from the parse result and evaluate it using an empty dictionary as the starting environment. Since IMP has no way to output any values to the terminal, we just print everything in the environment after the program is finished so we know that something actually happened.
Here is the canonical factorial example:
n := 5; p := 1; while n > 0 do p := p * n; n := n - 1 end
We evaluate this as follows:
$ ./imp.py hello.imp Final variable values: p: 120 n: 0
Conclusion
[In the last four articles,] we built an interpreter for a simple language from scratch. While the language itself is not very useful, the interpreter is extensible, and its major components (the lexer and parser combinator libraries) are reusable.
I hope this provides a good starting point for people to start experimenting with language design. Here are some ideas for exercises:
- Make variables local to the scope they are defined in (for instance, a variable defined in a loop should not be valid outside of the loop).
- Add a for-loop construct
- Add scan and print statements for user input and output
- Add functions